
Tous les ans nos étudiants doivent réaliser des projets. Nous leurs proposons des sujets et ils remplissent une fiche de vœux. Il faut ensuite satisfaire au mieux les étudiants. Évidement, certains sujets sont demandés par plusieurs groupes d’étudiants…
Un étudiant m’a demandé d’expliquer comment le problème était résolu, j’ai donc rédigé ces quelques lignes pour donner les grandes idées.
Les données du problème
A partir des fiches de vœux des étudiants une feuille de calcul est remplie avec une valeur représentant l’intérêt des étudiants pour le sujet. La valeur maximale de l’intérêt est donnée au premier sujet choisi par les étudiants et ainsi de suite. Les sujets qui n’ont pas été choisis par un groupe ont un intérêt de 0.
Les données peuvent être présentées ensuite sous la forme d’un tableau ayant l’aspect ci-dessous. Les lignes représentent les groupes (ici repérés de A à F) et les colonnes les sujets (repérés de 1 à 12). Le tableau est rempli à la main sous LibreOffice et exporté au format CSV (on peut aussi faire le CSV dans un éditeur de texte) en prenant soin d’ajouter un # dans la première colonne, il nous servira ensuite de marqueur pour repérer la première ligne.
| # Voeux | Sujet 1 | Sujet 2 | Sujet 3 | Sujet 4 | Sujet 5 | Sujet 6 | Sujet 7 | Sujet 8 | Sujet 9 | Sujet 10 | Sujet 11 | Sujet 12 |
| Groupe A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 4 | 3 | 2 | 1 |
| Groupe B | 5 | 0 | 4 | 0 | 3 | 0 | 2 | 0 | 1 | 0 | 0 | 0 |
| Groupe C | 5 | 4 | 3 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Groupe D | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 4 | 3 | 2 | 1 | 0 |
| Groupe E | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 3 | 4 | 5 |
| Groupe F | 0 | 0 | 5 | 0 | 4 | 0 | 3 | 0 | 2 | 0 | 1 | 0 |
Le fichier CSV est donc le suivant :
# Voeux,Sujet 1,Sujet 2,Sujet 3,Sujet 4,Sujet 5,Sujet 6,Sujet 7,Sujet 8,Sujet 9,Sujet 10,Sujet 11,Sujet 12 Groupe A,0,0,0,0,0,0,0,5,4,3,2,1 Groupe B,5,0,4,0,3,0,2,0,1,0,0,0 Groupe C,5,4,3,2,1,0,0,0,0,0,0,0 Groupe D,0,0,0,0,0,0,5,4,3,2,1,0 Groupe E,0,0,0,0,0,0,0,1,2,3,4,5 Groupe F,0,0,5,0,4,0,3,0,2,0,1,0
Lecture des données
A partir du fichier CSV il faut extraire trois tableaux :
- le premier contenant les groupes
- le deuxième contenant les sujets
- le troisième (2D) contenant les vœux.
La disposition des données dans le fichier CSV permet de construire le tableau des sujets avec la première ligne. Ensuite le tableau contenant les groupes et le tableau contenant les vœux sont remplis au fur et à mesure de la lecture du fichier.
A partir de la double liste contenant les vœux, on construit un tableau de type numpy.array (avec le temps je travaille de plus en plus avec numpy pour les représentations de tableau).
import sys
import csv
import numpy as np
def lire_voeux(fic="exemple.csv"):
tmp = []
groupes = []
voeux = []
with open(fic) as fic:
reader = csv.reader(fic, delimiter=',')
for ligne in reader:
if '#' in ligne[0]:
tmp, sujets = ligne[0], ligne[1:]
else:
groupe, voeux_ = ligne[0], [int(_) for _ in ligne[1:]]
groupes.append(groupe)
voeux.append(voeux_)
return sujets, groupes, np.array(voeux)La fonction retourne les 3 tableaux qui seront utilisés par la suite.
Approche exhaustive
Ce problème rentre dans la catégorie des problèmes d’affectation, de nombreux algorithmes existent (algorithme hongrois,…) et il doit être possible de résoudre ce problème en modifiant les algorithmes existants. Je n’ai pas pris le temps de réfléchir à un algorithme complet permettant de résoudre ce problème.
Espace de recherche
Parmi l’ensemble des sujets proposés il est possible que certains ne soient pas du tout retenus par les étudiants. A l’inverse, il faut qu’il y ait au moins autant de sujet retenus (indépendant de leurs position) que de groupes d’étudiants (dans ce cas il risque toutefois d’avoir beaucoup d’étudiants insatisfaits).
L’utilisation d’un numpy.array pour représenter les vœux permet de vérifier tout ça rapidement. La somme de chaque colonne (selon la représentation de notre tableau ci-dessus) permet de retrouver ensuite facilement les sujets qui n’ont jamais été retenus par les étudiants. Le nombre de sujets retenus doit être supérieur ou égal au nombre de groupes sinon le problème est insolvable.
somme_voeux = np.sum(voeux, axis=0)
sujets_possibles = np.where(somme_voeux>0)[0]
if (sujets_possibles.shape[0]<len(groupes)):
print("Pas assez de sujets retenus")
sys.exit()Représentation d’une solution
Dans l’exemple précédent le tableau sujets_possibles contient [ 0 1 2 3 4 6 7 8 9 10 11]. Le sujet 6 (ayant l’indice 5 dans le tableau) n’ayant pas été retenu par les étudiants.
Une solution au problème est représentée par un tableau ayant pour taille le nombre de groupes. Chaque cas du tableau contenant l’indice du sujet (dans le tableau sujets).
| Groupe | Groupe A | Groupe B | Groupe C | Groupe D | Groupe E | Groupe F |
| Sujet attribué | Sujet 1 | Sujet 2 | Sujet 3 | Sujet 4 | Sujet 5 | Sujet 7 |
La solution présentée précédemment s’écrit simplement en Python avec un tranche dans la liste sujets_possibles.
solution = sujets_possibles[0:len(groupes)]Qualité d’une solution
Partant d’une solution il faut être capable d’évaluer la qualité de la proposition, après avoir lu dans le tableau choix la satisfaction de chaque groupe plusieurs approches peuvent être utilisées :
- calculer la moyenne,
- rechercher l’amplitude et le nombre de vœux minimaux (on cherchera donc à minimiser ce critère),
- rechercher l’amplitude et le nombre de vœux maximaux,
- …
Nous allons simplement utiliser la moyenne de la satisfaction comme qualité d’une proposition d’attribution de projets.
Pour chaque groupe on cherche le sujet qui lui a été attribué (contenu dans la liste attributions passée en paramètre) et on recherche dans le tableau des vœux la valeur d’intérêt pour ce projet.
On somme ces valeurs pour tous les groupes et on calcule la moyenne. Le but va être de maximiser cette valeur. Dans le cas ci-dessus, idéalement il faudrait une moyenne de 5 (ce qui signifierait que tous les groupes ont eu leur premier vœu).
def __calculer_satisfactions(attributions, voeux):
somme = 0.0
for idx,sujet in enumerate(attributions):
somme += voeux[idx][sujet]
return somme/len(attributions)La solution initiale présentée ci-dessus donne les valeurs suivantes :
| Groupe | Groupe A | Groupe B | Groupe C | Groupe D | Groupe E | Groupe F |
| Sujet attribué | Sujet 1 | Sujet 2 | Sujet 3 | Sujet 4 | Sujet 5 | Sujet 7 |
| Satisfaction (max. 5) | 0 | 0 | 3 | 0 | 0 | 3 |
La satisfaction totale est de 6 et la satisfaction moyenne est de 1. La solution est très mauvaise, la majorité des groupes ayant des sujets qu’ils ne voulaient pas.
Recherche de la meilleure solution
Le problème du choix de 

$$A^k_n = \frac{n!}{(n-k)!}\quad\mbox{pour }k\leq n $$
Le nombre possible explose en fonction du nombre de groupes (et du nombre de vœux possibles),
Dans l’exemple précédent (5 vœux, 6 groupes et 11 vœux retenus) le nombre de combinaisons est de 332640.
En Python le module itertools permet de traiter les différents cas de permutations, combinaisons, arrangement,… A partir des sujets_possibles la liste des solutions possibles est construite avec :
solutions_possibles = list(itertools.permutations(sujets_possibles, len(groupes)))
print("Nombre de combinaisons : ", len(solutions_possibles))L’ensemble des solutions étant construit, il reste à rechercher la meilleure (ou les meilleures, il peut y avoir plusieurs solutions optimales). Une simple compréhension de liste sur les solutions possibles qui utilise la fonction __calculer_satisfaction précédemment écrite permet de trouver la qualité de toutes les solutions. Ensuite il suffit de recherche la valeur maximale et la solution associée :
valeurs_solutions = [__calculer_satisfactions(_, voeux) for _ in solutions_possibles]
meilleur_satisfaction = max(valeurs_solutions)
meilleur_solution = valeurs_solutions.index(meilleur_satisfaction)La solution (dans ce cas elle est unique) est :
| Groupe | Groupe A | Groupe B | Groupe C | Groupe D | Groupe E | Groupe F |
| Sujet attribué | Sujet 8 | Sujet 1 | Sujet 2 | Sujet 7 | Sujet 12 | Sujet 3 |
| Satisfaction (max. 5) | 5 | 5 | 4 | 5 | 5 | 5 |
La satisfaction moyenne est de 4,83. Tous les groupes ont leurs premiers vœux sauf le groupe C qui obtient son deuxième vœu.
Approche heuristique
La construction de l’ensemble des solutions possibles devient très vite impossible en un temps (et une quantité de mémoire) raisonnable. Cette année nous avons (sur les deux promotions) une vingtaine de groupe et une trentaine de sujet, le nombre de solutions est d’environ 
Modification d’une solution
Le tableau sujets_possibles contient tous les sujets retenus par les étudiants. La solution du problème est construite à partir d’une tranche contenant les premiers éléments.
solution = sujets_possibles[0:len(groupes)]La permutation de deux éléments dans l’ensemble des sujets possibles peut conduire à une meilleure solution. Pour éviter de calculer des solutions inutiles (celles pour lesquelles les permutations sont hors du tableau solution) l’intervalle de tirage de l’un des deux éléments est limité à l’intérieur de solution.
Après la permutation des éléments, l’efficacité de la solution est calculée, si elle est plus mauvaise que la valeur précédente, les éléments permutés sont replacés à leurs positions initiales. Cette séquence est répétée pendant quelques milliers d’itérations.
import random
#...
def attribuer_projet_aleatoire(groupes, sujets, voeux):
NB_REP = 2000
somme_voeux = np.sum(voeux, axis=0)
sujets_possibles = np.where(somme_voeux > 0)[0]
if (sujets_possibles.shape[0] < len(groupes)):
print("Pas assez de sujets retenus")
exit(1)
evolutions = np.zeros(NB_REP)
for _ in range(NB_REP):
satisfaction = __calculer_satisfactions(sujets_possibles[0:len(groupes)], voeux)
evolutions[_] = satisfaction
a = random.randint(0,len(groupes)-1)
b = random.randint(0, sujets_possibles.shape[0]-1)
sujets_possibles[b], sujets_possibles[a] = sujets_possibles[a], sujets_possibles[b]
satisfaction_ = __calculer_satisfactions(sujets_possibles[0:len(groupes)], voeux)
if satisfaction > satisfaction_:
sujets_possibles[b], sujets_possibles[a] = sujets_possibles[a], sujets_possibles[b]
return __calculer_satisfactions(sujets_possibles[0:len(groupes)], voeux), sujets_possibles[0:len(groupes)], evolutionsLa fonction s’appelle à partir des éléments construit précédemment, elle retourne la satisfaction moyenne finale, l’attribution des projets et l’évolution de la satisfaction (afin de construire ensuite les graphiques d’évolution)
satisfaction, attributions, evolutions = attribuer_projet_aleatoire(groupes, sujets, voeux)Résultats
Dans le cas de l’exemple proposé il est facile de vérifier l’efficacité de l’algorithme : la solution globale est connue et le nombre de permutations possible est connu. Dans les illustrations ci-dessous l’algorithme a réalisé 2000 itérations (à comparer aux 332640 cas possibles).

Avec 2000 itérations, l’algorithme a calculé 0.6% des permutations possibles, ce qui représente un temps de calcul et une occupation en mémoire bien inférieur à la recherche de la solution de manière exhaustive (sous réserve quelle soit possible).
Dans certains cas, l’algorithme ne converge pas vers la solution globale et se trouve pris dans un optimum local.

Dans l’exemple ci-contre le maximum global n’a pas pu être atteint. L’algorithme a convergé vers un maximum local. Dans le cas de notre problème il s’agit d’une solution pas trop mauvaise qui ne pourrait être améliorée qu’en réalisant plusieurs permutations (avec certaines qui conduiraient à une solution plus mauvaise).
Amélioration avec un algorithme de recuit simulé
Pour quitter les optimums locaux, il est nécessaire d’utiliser un algorithme capable de réaliser des modifications plus importantes que la permutation de 2 éléments. J’ai choisi de manière arbitraire 😉 d’utiliser un algorithme de recuit simulé qui est simple à coder et qui donne souvent de bons résultats pour ce type de problèmes.
Principe
L’algorithme du recuit simulé est une métaheuristique permettant de minimiser la fonction d’énergie 
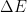
- si
l’énergie est diminuée, la nouvelle configuration du système est conservée.
- si
l’énergie est augmentée, la nouvelle configuration a une probabilité (donc comprise entre 0 et 1) d’être retenue donnée par
. Cette probabilité d’acceptation liée à une fonction exponentielle décroissante est appelée règle de Métropolis.
La température 
Application
L’application de l’algorithme du recuit simulé à notre problème est assez simple. L’énergie du système correspond à la valeur de satisfaction à la nuance près qu’il faut la maximiser (et pas la minimiser comme dans l’algorithme de recuit simulé).
Une variation de la configuration du système est simplement la permutation de deux éléments dans le tableau des sujets retenus (comme dans le programme précédent).
Réglage des différents paramètres
Les algorithmes basés sur des métaheuristiques sont souvent compliqués à régler. Les paramètres sont nombreux et souvent interdépendants. Dans le cas du recuit il existe toutefois quelques règles empiriques qui permettent d’obtenir de bons résultats et une convergence rapide.
Estimation de la variation moyenne
Pour pouvoir fixer la température initiale il est nécessaire de connaître une estimation de la variation moyenne de l’énergie notée 
def __calcul_variation_moyenne(voeux,NB=500):
diff = 0
somme_voeux = np.sum(voeux, axis=0)
sujets_possibles = np.where(somme_voeux > 0)[0]
satisfaction = __calculer_satisfactions(sujets_possibles[0:len(groupes)], voeux)
for _ in range(NB):
a = random.randint(0,len(groupes)-1)
b = random.randint(0, sujets_possibles.shape[0]-1)
sujets_possibles[b], sujets_possibles[a] = sujets_possibles[a], sujets_possibles[b]
satisfaction_ = __calculer_satisfactions(sujets_possibles[0:len(groupes)], voeux)
diff += np.abs(satisfaction_ - satisfaction)
satisfaction = satisfaction_
return diff / NBLa fonction est utilisée lors de l’initialisation de l’algorithme de recuit simulé pour calculer la température initiale.
Température initiale
La température initiale est donnée par :
Le facteur 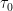

delta_E = __calcul_variation_moyenne(voeux)
T_0 = (-1.0 * delta_E) / np.log(0.50)
T = T_0Évolution de la température
La température doit diminuer pour que l’algorithme converge (pour que la probabilité d’acceptation des « mauvaises » solutions diminue). Plusieurs lois sont utilisées, une solution simple est de multiplier la température par 0,95 après un certain nombre de permutations selon le nombre de variables à optimiser. Pour ce problème, j’ai choisi de mettre à jour la température après 50 permutations. Pour un nombre de sujets/groupes plus important cette valeur doit être augmenté en conséquence (elle pourrait être configurée automatiquement…).
if _ % 50 == 0:
T = 0.9 * TSauvegarde du meilleur rencontré
Puisque l’algorithme conserve des solutions de moins bonnes qualités pour quitter les optimums locaux, il est possible de perdre la meilleure solution trouvée. Pour éviter ce problème il suffit de sauvegarder la meilleure solution connue ainsi que sa valeur.
if satisfaction_>meilleure_satisfaction:
meilleure_satisfaction = satisfaction_
meilleure_solution = np.array(sujets_possibles[0:len(groupes)])
Critères d’arrêt
Bien que l’algorithme soit très rapide il peut être intéressant de l’arrêter si certains critères sont vérifiés :
- la satisfaction a atteint le maximum possible (donc ici 5)
- la satisfaction stagne pendant plusieurs centaines d’itérations ; l’écart type des valeurs est donc très faible.
if meilleure_satisfaction==5 or (_>200 and np.std(evolutions[_-200:_])<0.0001):
return meilleure_satisfaction, meilleure_solution, evolutionsCode complet
Les morceaux de programme présentés ci-dessus sont assemblés pour construire la fonction complète.
def attribuer_projet_recuit(groupes, sujets, voeux):
NB_REP = 2000
# Extraction des sujets retenus
somme_voeux = np.sum(voeux, axis=0)
sujets_possibles = np.where(somme_voeux > 0)[0] # Seulement les non nuls
if (sujets_possibles.shape[0] < len(groupes)):
print("Pas assez de sujets retenus")
sys.exit()
evolutions = np.zeros(0)
# Calcul de la variation moyenne
delta_E = __calcul_variation_moyenne(voeux)
T_0 = (-1.0 * delta_E) / np.log(0.50)
T = T_0
# Sauvegarde du meilleur rencontré
meilleure_satisfaction = __calculer_satisfactions(sujets_possibles[0:len(groupes)], voeux)
meilleure_solution = sujets_possibles[0:len(groupes)]
satisfaction = meilleure_satisfaction
for _ in range(NB_REP):
# Mise à jour de la température
if _ % 50 == 0:
T = 0.9 * T
# Valeurs de permutations
a = random.randint(0, len(groupes) - 1)
b = random.randint(0, sujets_possibles.shape[0] - 1)
sujets_possibles[b], sujets_possibles[a] = sujets_possibles[a], sujets_possibles[b]
satisfaction_ = __calculer_satisfactions(sujets_possibles[0:len(groupes)], voeux)
diff = satisfaction_ - satisfaction
# Valeurs pour le recuit
r = np.random.random()
seuil = np.exp(1.0 * diff / T)
# Solution trop mauvaise pour le recuit
if diff < 0 and r > seuil:
sujets_possibles[b], sujets_possibles[a] = sujets_possibles[a], sujets_possibles[b]
else:
satisfaction = satisfaction_
# Sauvegarde de la meilleur solution
if satisfaction_>meilleure_satisfaction:
meilleure_satisfaction = satisfaction_
meilleure_solution = np.array(sujets_possibles[0:len(groupes)])
evolutions = np.append(evolutions, satisfaction)
# Conditions d'arrêt
if meilleure_satisfaction==5 or (_>200 and np.std(evolutions[_-200:_])<0.0001):
return meilleure_satisfaction, meilleure_solution, evolutions
return meilleure_satisfaction, meilleure_solution, evolutionsRésultats
Il n’y a pas de garantie théorique que l’optimum global soit attend par l’algorithme. En pratique, si on exécute plusieurs fois l’algorithme, l’optimum est généralement atteint en un nombre assez faible d’itérations.

La valeur de la satisfaction moyenne n’évolue plus de manière monotone car le recuit autorise des « mauvaises » solutions. Le recuit permet de quitter les optimums locaux et d’attendre l’optimum globale. Aux environs des 700 itérations, l’apport du recuit est bien visible : l’algorithme convergeait vers une solution locale de 4,66 avant le recuit, le recuit a permis de trouver la valeur 4,83
Le critère d’arrêt sur la stabilité a arrêté l’algorithme en moins de 1000 itérations (il faut prendre en compte celle qui ont été nécessaire pour calculer la variation moyenne nécessaire pour fixer les paramètres de l’algorithme).
Mise en œuvre
Cette année nous avons 20 groupes de projets qui ont retenu au total 26 sujets différents. Le calcul de l’arrangement conduit à 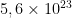
- le nombre de répétitions est augmenté à 10000
- la température est actualisée toutes les 250 itérations
- la convergence est fixée pour un écart-type très faible après 5000 itérations
L’algorithme converge en quelques secondes. J’ai réalisé des répétitions qui ont montré que plusieurs configurations différentes semblaient conduire au maximum possible (il n’est pas certain que ce soit le maximum, mais c’est fort probable…).
Inventaire des différentes solutions
Puisque le problème admet plusieurs solutions équivalentes, l’algorithme ne peut pas choisir la meilleure. La solution la plus simple est d’essayer de faire l’inventaire des solutions possibles et de les stocker dans un fichier.
Pour construire un inventaire des solutions possible, la fonction attribuer_projet_recuit va être appelée plusieurs fois et les résultats des différentes itérations vont être stockés. La satisfaction maximale est ensuite recherchée.
Chaque solution telle que sa valeur de satisfaction soit égale à la satisfaction maximale est ensuite stockée dans un set ce qui assure l’unicité de la solution dans l’ensemble des solutions qui seront conservées. La solution doit être transformée en tuple (qui est immuable) pour pouvoir être stockée dans l’ensemble meilleures_solutions. Après le remplissage de l’ensemble des meilleures_solutions, il ne reste plus qu’à écrire les éléments dans un fichier CSV :
- la première ligne contient les noms des groupes
- les lignes suivantes stocke les différentes configurations possibles.
def recherches_multiples(groupes, sujets, voeux, nb_rep=100, fic="solutions.csv"):
solutions = []
valeurs = []
satisfaction_maximale = 0.0
for _ in range(nb_rep):
satisfaction, attributions, evolutions = attribuer_projet_recuit(groupes, sujets, voeux)
solutions.append(attributions)
valeurs.append(satisfaction)
satisfaction_maximale = max(valeurs)
print("Satisfaction maximale : ", satisfaction_maximale)
meilleures_solutions = set()
for s, v in zip(solutions, valeurs):
if v == satisfaction_maximale:
meilleures_solutions.add(tuple(s))
print("%d configurations différentes trouvées"%(len(meilleures_solutions)))
with open(fic, 'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(groupes)
for s in meilleures_solutions:
writer.writerow([sujets[int(_)] for _ in s])Le fichier CSV obtenu peut ensuite être mis en forme avec Libre Office et envoyé aux enseignants qui trancheront 😉 .
Notes
Les éléments de code n’ont pas nécessairement été écrit de manière optimale mais plutôt de telle manière que les points principaux des explications puissent être retrouvés dans le code.
Les valeurs de pondérations associées aux vœux des étudiants peuvent être modifiées en fonctions de différents critères (les enseignants peuvent vouloir privilégier tel ou tel groupe sur un projet,…).
Le livre Métaheuristiques des éditions Eyrolles est une saine lecture pour découvrir et approfondir le sujet.
Tout le code est présent sur un dépôt Gitlab ou sur Github.